目录
1.研究概述
2.论文创新
2.1 改进生成器的网络框架
2.2 改进判别器
2.3 改进感知损失
2.4 网络插值
3.实验
3.1 评价指标
3.2 训练细节
3.3 对比实验
3.4 消融实验
3.5 网络插值
4.总结
5.阅读参考
文章标题:《ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks》
发表年份及会议:ECCV2018
文章地址:ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks (arxiv.org)![]() https://arxiv.org/abs/1809.00219
https://arxiv.org/abs/1809.00219
代码地址:https://github.com/xinntao/ESRGAN![]() https://github.com/xinntao/ESRGAN
https://github.com/xinntao/ESRGAN
1.研究概述
超分辨率生成对抗网络(SRGAN)能够生成逼真的纹理,但是不可避免地会出现伪影。作者为了提高生成图像的视觉质量,针对SRGAN中的组件和设计进行了改进,并提出ESRGAN。相比SRGAN而言作者提出的模型有更好的生成质量,更自然的纹理,并在PIRM2018-SR Challenge中获得第一名

2.论文创新
作者在SRGAN上提出如下改进:
- 改进生成器网络框架
- 改进判别器 Discriminator
- 改进感知损失 Perceptual Loss
- 为了减少噪声,提出使用网络插值
2.1 改进生成器的网络框架
下图为SRGAN的框架图:

作者主要针对其中的basic block进行改进,移除了所有的BN层,并将RB模块替换成了RRDB模块

作者认为移除BN层能够减少计算复杂度,并提高模型性能。由于在验证时BN层的计算运用整个数据集的平均值和方差,而在训练时用了一个batch的平均值和方差,所以当训练集与测试集不同时BN的效果就会较差,模型的泛化能力受到了限制。RRDB模块采用了residual-in-residual结构,结合了多级残差网络和dense连接,提高了残差学习的层次,同时笔者认为RRDB模块能够使网络保持底层的特征,因此生成出的图像细节更丰富。
为了能够训练更深的网络,作者对网络做了两点小改进:
1)在dense block进入主路径前,作者加入了β残差缩放参数,保持训练的稳定性
2)让初始化参数时的方差较小,使得残差结构更容易训练
2.2 改进判别器
传统的鉴别器估计输入图像是否真实和自然的概率(绝对),而作者提出相对鉴别器Relativistic GAN,尝试预测真实图像相对于假图像
更真实的概率(相对)
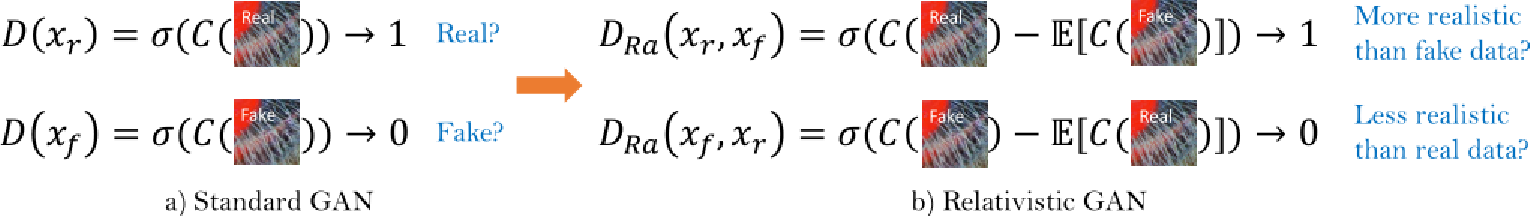
其中,σ为激活函数,C(x)为未转换的鉴别器的输出,E[·]表示对batch中所有假数据取平均值的操作。因此可以得出判别器的损失为:
![]()
对抗损失为:
![]()
判别器的改进能够学习到更清晰的边界和更细节的纹理
2.3 改进感知损失
在之前的研究中SRGAN,感知损失是定义在激活层后的,这使得激活的特征间距离达到了最小化,这种方式得到的特征十分稀疏,并且激活的神经元的平均百分比在经过激活层后会衰减,导致了较差的监督能力,并且运用激活后的特征会使得最终的结果亮度不一致
最终,生成器的损失为:
![]()
![]()
其中,L1为content loss,λ和η为超参数用于平衡不同的损失
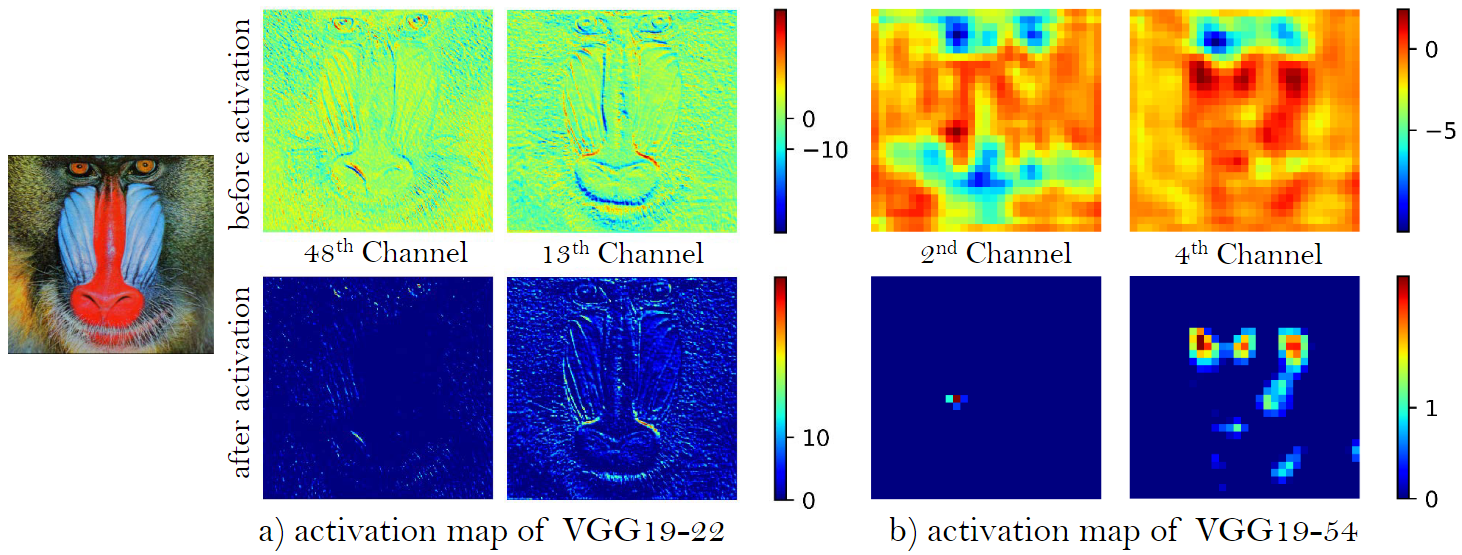
随着网络的加深,大部分特征在激活后变得不活跃,而在激活前的特征包含有更多信息
2.4 网络插值
为了减少基于GAN方法产生的噪声同时维持较好的感知质量,作者提出使用网络插值的方法。首先训练一个PSNR为导向的网络GPSNR,然后微调得到基于GAN的网络GGAN,通过这两个网络相应元素间的插值得到插值模型GINTERP:
![]()
θ为各个参数。插值模型一方面对于任意可行α能够产生有用的结果同时不带来伪影,另一方面不用重新训练模型就能平衡感知质量与保真度
作者还探索了其他的插值方案,比如直接插值两个网络的输出图像,这种方式不能很好平衡噪声与模糊度,又比如微调λ和η,这种方式成本太昂贵
3.实验
3.1 评价指标
①传统的方法常用PSNR作为指标,但这种方法因为与人类的主观评估往往会输出过平滑的结果,缺少高频细节
②这个比赛还采用了另一个指标,perceptual index
![]()

perceptual index越低感知质量越来,作者提出的模型主要是在R3区域中
3.2 训练细节
LR由HR通过matlab的bicubic退化4倍所得。HR分辨率是128×128,LR的分辨率则是32×32,mini-batch=16。
训练过程分为两步骤:
1)先通过重建损失训练一个base模型,论文中使用的重建损失是L1。
2) 训练好base模型加入gan loss 和perceptual loss进行微调。
这样训练的好处是base模型:
1)可以给gan模型一个更好的初始化,毕竟gan的训练比较动荡
2)判别器一开始接受的SR的输入不会太差,这样可以让判别器更加关注到纹理的判别上,而不是还需要判别结构等信息。
在ESRGAN中使用的RRDB的个数是23。
3.3 对比实验
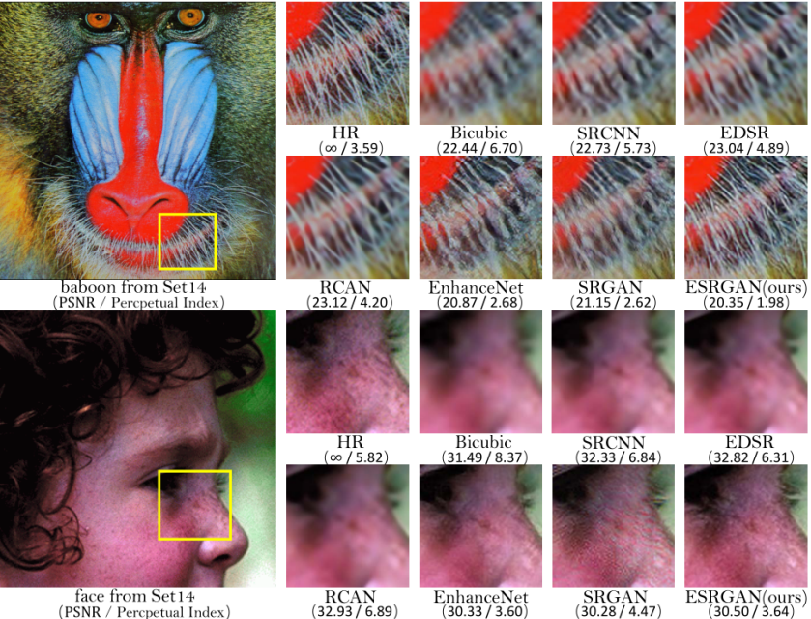
LR图像从HR图像下采样得到,作者还运用了图像翻转和旋转的数据增强方式。其中,Bicubic为下采样结果,SRCNN、EDSR、RCAN为RSNR导向的方法,EnhanceNet、SRGAN、ESRGAN为基于GAN的方法
分析可知,ESRGAN有更清晰和更细节的特征。PSNR导向的方法容易产生模糊的结果,而之前基于GAN的方法会有不自然和噪声的出现,并且偶尔会有伪影
3.4 消融实验

通过对结果的分析可知:
①在移除BN层后并没有减弱模型性能,同时还维持了计算资源和内存占用。作者还进一步进行了实验表明当网络加深后,带有BN层可能会产生伪影

②使用激活前的特征会使结果的亮度更精准。直方图的结果表明运用激活后的特征会使颜色分布向左偏离,导致图像更昏暗,而使用激活前的特征更接近真实值。同时图(b)表明使用激活后的特征能得到更清晰的边缘和更丰富的纹理

③相对的鉴别器能够学习到更清晰的边界和更多细节纹理
④更深层的网络有更强的表达能力从而捕捉更多的语义信息,能够提高图像的纹理并减少噪声。同时由于RRDB模块没有携带BN层使得深层网络也能很好训练
⑤作者还发现当数据集更大时生成器能产生更自然的结果
3.5 网络插值

作者比较了网络插值和图像插值策略,单纯基于GAN的方法能产生更清晰的边缘和更丰富的纹理,但会有一些伪影;而单纯PSNR导向的方法会输出较模糊的图像,通过采用插值,能在这两者之间达到平衡
4.总结
作者提出了一种有更好感知质量的ESRGAN模型,其中包含多个不携带BN层的RDDB模块,还使用了残差缩放和较小初始化等技术来促进深度模型的训练。作者引入了相对GAN作为鉴别器,学习判断一个图像是否比另一个图像更真实,引导生成器恢复更细节的纹理,并通过使用在激活之前的特征来增强感知损失,提供更强的监督,从而得到更准确的亮度和逼真的纹理
5.阅读参考
文献阅读: ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks_perceptual index-CSDN博客
超分辨率论文阅读—ESRGAN(2018ECCV) - 知乎 (zhihu.com)







![[C++] const 成员函数](https://img-blog.csdnimg.cn/direct/884b272cec4f4d5294564e1403901c3b.png)